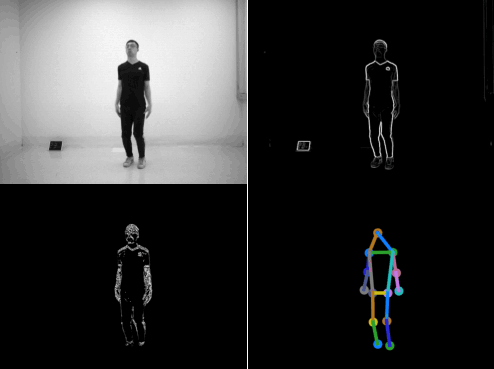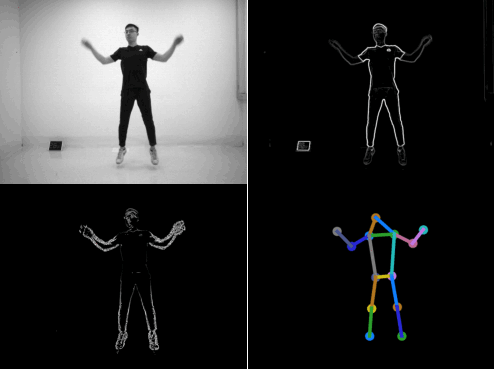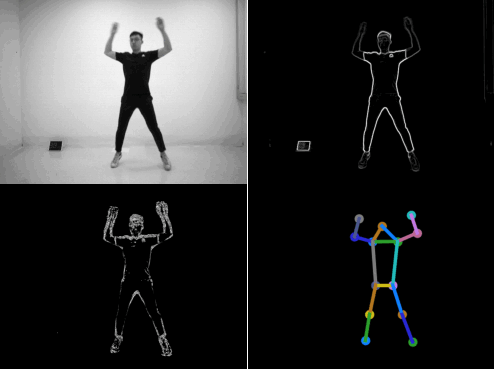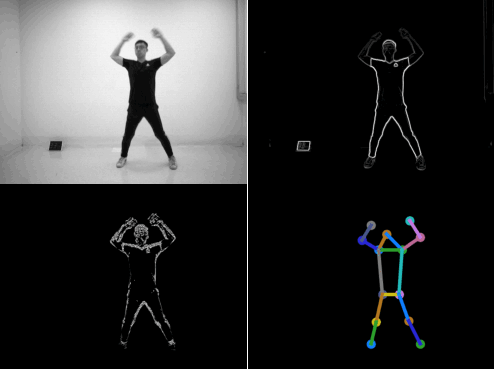
Figure 1. SPHP dataset. Our motion vector sensor (MVS) extracts edge images and two-directional motion vector images at each time frame. We also provide annotated body joints for human poses and corresponding grayscale images.
Abstract
We propose a sparse and privacy-enhanced representation for Human
Pose Estimation (HPE). Given a perspective camera, we use a
proprietary motion vector sensor (MVS) to extract an edge image and
a two-directional motion vector image at each time frame. Both edge
and motion vector images are sparse and contain much less information
(i.e., enhancing human privacy). We advocate that edge information
is essential for HPE, and motion vectors complement edge information
during fast movements.
We propose a fusion network leveraging recent
advances in sparse convolution used typically for 3D voxels to
efficiently process our proposed sparse representation, which achieves
about 13x speed-up and 96% reduction in FLOPs. We collect an in-house
edge and motion vector dataset with 16 types of actions by 40 users
using the proprietary MVS. Our method outperforms individual modalities
using only edge or motion vector images. Finally, we validate the
privacy-enhanced quality of our sparse representation through face
recognition on CelebA (a large face dataset) and a user study on our
in-house dataset.
SPHP Dataset
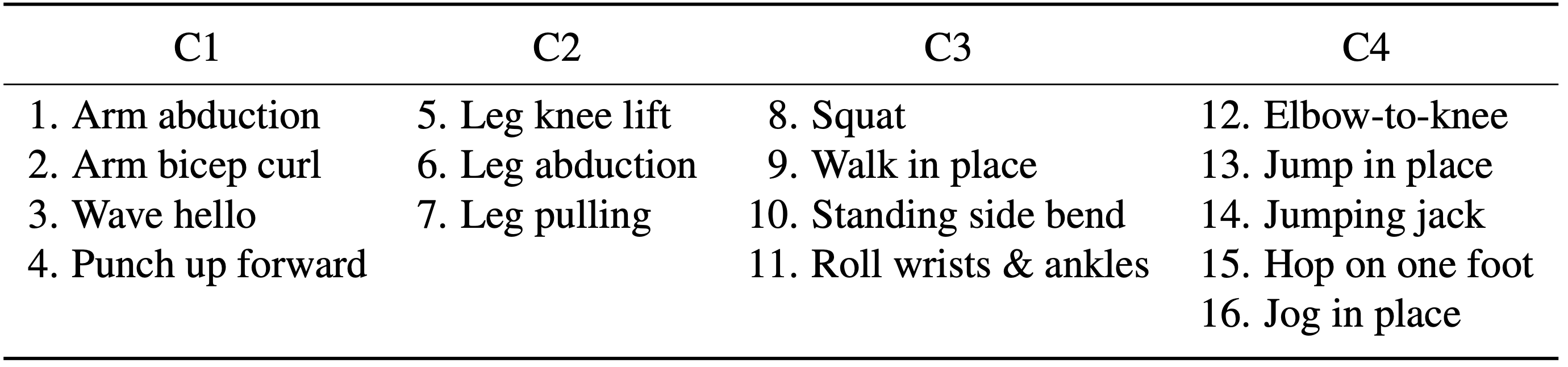
Table 1. The 16 actions in our SPHP dataset are categorized into four classes: C1 for upperbody movements, C2 for lower-body movements, C3 for slow whole-body movements, and C4 for fast whole-body movements.
We introduce the Sparse and Privacy-enhanced Dataset for Human Pose
Estimation (SPHP), which consists of synchronized,
complementary images of edge and motion vectors along with ground
truth labels for 13 joints.
We collect data from 40 participants (20 male and 20 female).
Participants performed 16 fitness-related actions, which are
categorized into four classes based on the type of movement.
Sparse Representation
- Edge Image MVS uses an efficient hardware implementation of edge detection, similar to Canny edge detection, to generate edge images. Each pixel in the edge image has a value within the range of $\{0, 255\}$. A higher value indicates a stronger intensity of the edge.
- Motion Vector Inspired by the motion detection of the Drosophila visual system and designed with patent-pending pixel-sensing technology, MVS detects vertical and horizontal motion vectors, denoted as $MV_X$ and $MV_Y$, by analyzing changes in illumination. Each value falls within the range of $\{-128, 128\}$. The magnitude and sign of a value represent the strength and direction of motion.
Fusion Model
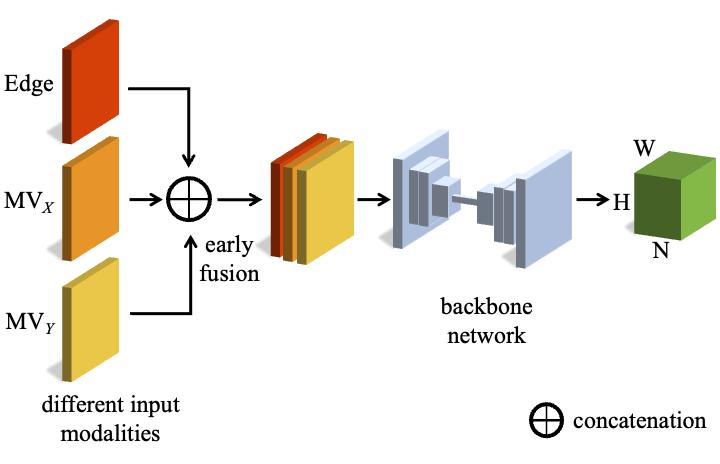
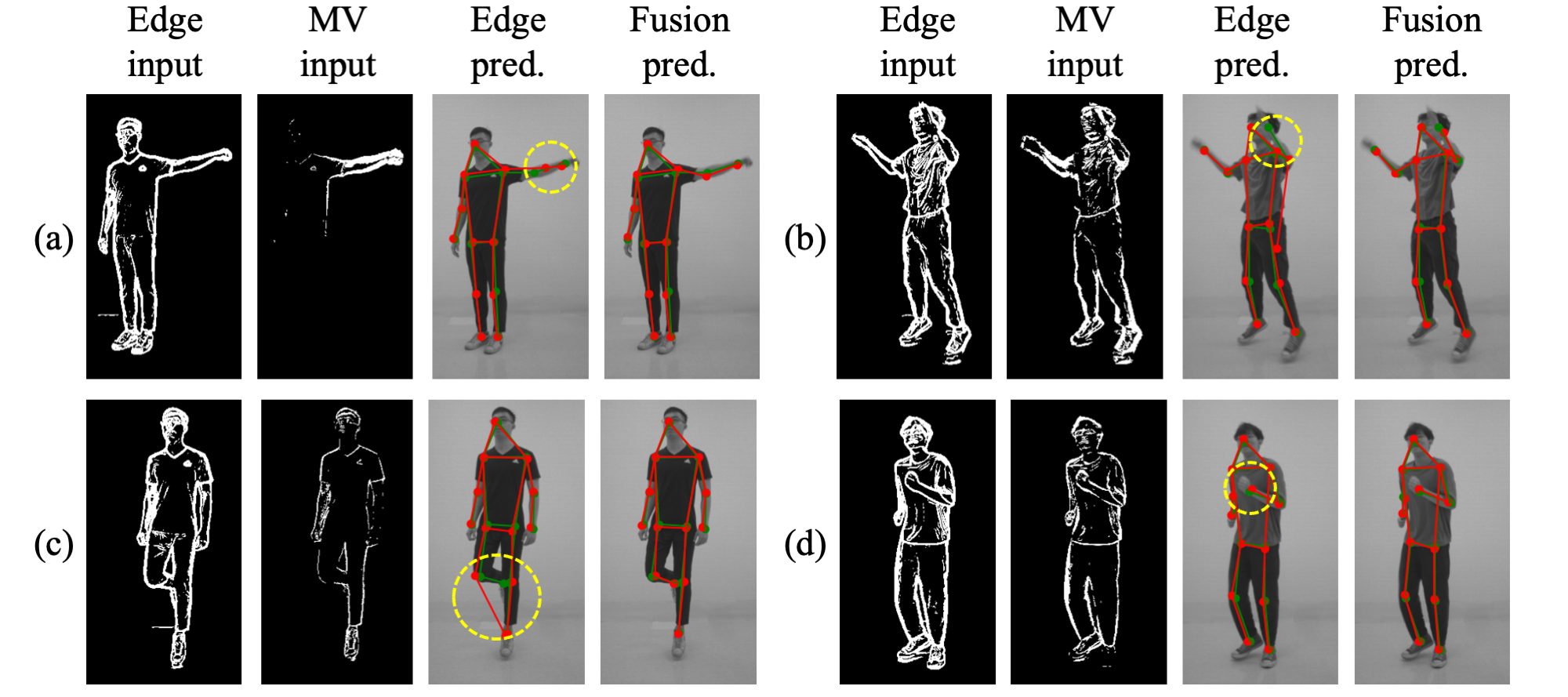
Edge and motion vector information complement each other. While edge
is sufficient for detecting clear and non-blurred body joints,
incorporating motion vectors into our model can effectively address
the challenges posed by fast movements and overlapping boundaries,
which may confuse edge-based HPE models.
Hence, we aim to combine the complementary information of edge and
motion vectors while keeping our model compact and efficient. We
directly concatenate an edge image and a two-directional motion
vector image, proposing the early fusion model (referred to as FS)
as illustrated in the figure below. Our FS model can leverage
various single-branch network architectures designed for compactness
and efficiency.
Evaluation Metric
Mean Per Joint Position Error (MPJPE) is chosen for evaluation. It calculates the Euclidean distance between predicted positions $\hat{y_{i}}$ and ground truth positions $y_{i}$ for each joint, where $N$ is the number of joints.
Experiments
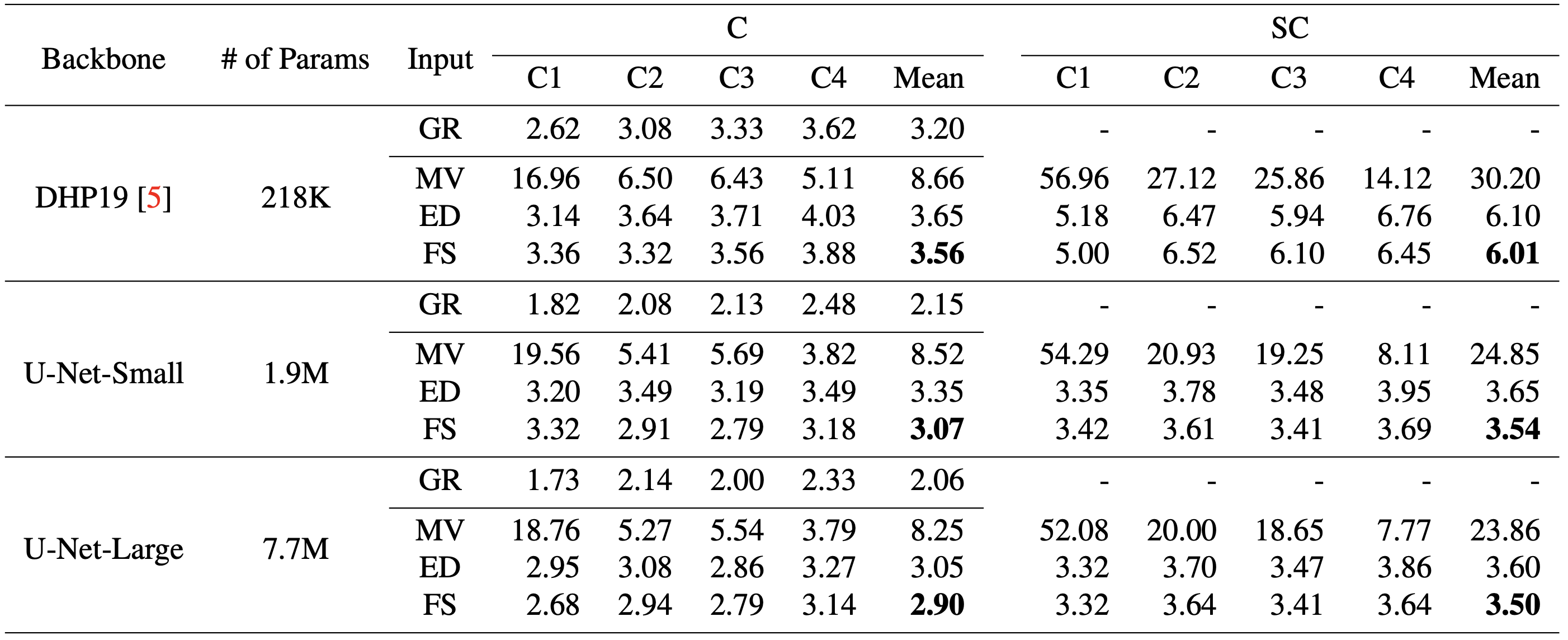
Table 2. MPJPE (lower is better) on SPHP with different input types. Different input modalities, "GR", "ED", "MV", and "FS", are grayscale, edge, motion vector, and fusion (edge and motion vector), respectivetly. C1, C2, C3, C4 are four classes listed in Table 1. C and SC are traditional and sparse convolutions, respectively.
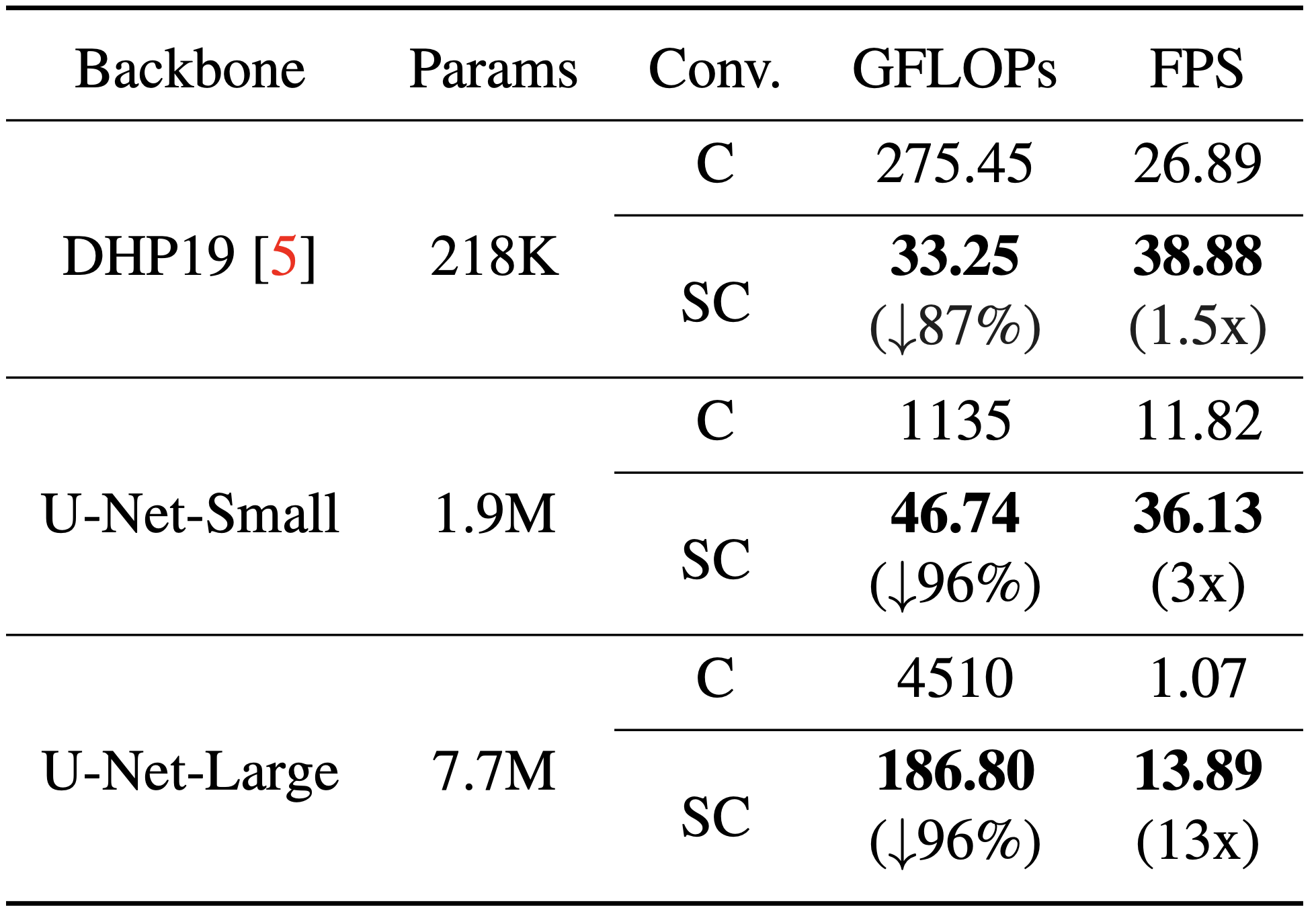
Table 3. Comparison of GFLOPs and FPS (frames per second). All of the experiments are conducted for the fusion input modality on SPHP.
Visualization